

Data Governance Does Not Scale
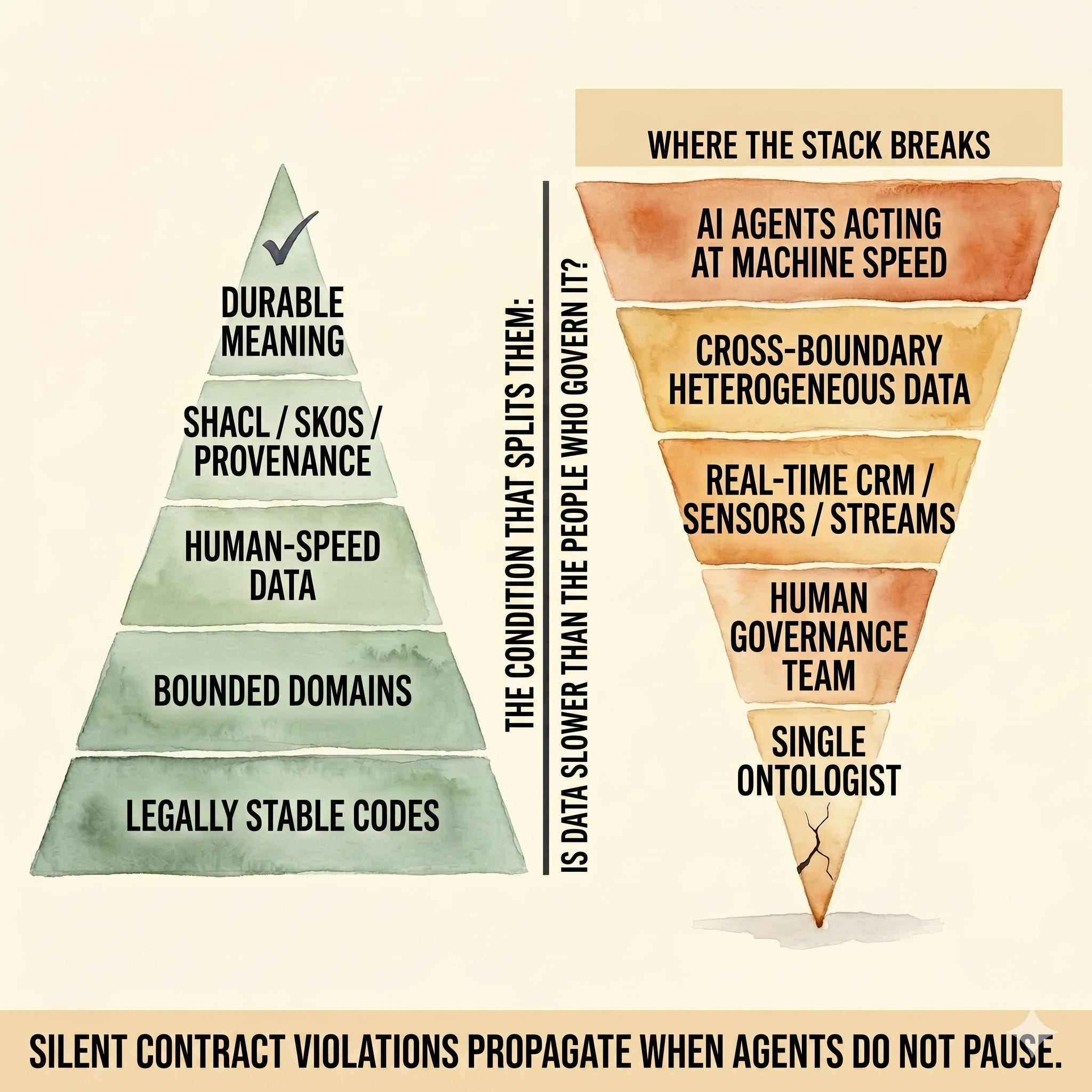
The durability stack is real. The direction of travel is not.
This essay continues the exchange with Veronika Heimsbakk, whose response to Semantically Rich, Temporally Unanchored is technically precise and worth reading in full. This essay accepts her durability stack, acknowledges where it works, and asks the question it does not answer: what happens when the data moves faster than the people who govern it?
In 2012, Bob Page, VP of Analytics at eBay, said something the data community heard and did not act on. “The future is live.” “Up-to-date means before the next click.” “The business cannot be held back by the slowest data feed.” He was describing a digital marketplace. He was naming the direction every data-intensive organisation was already heading, regardless of industry, regardless of data type, regardless of whether they had a single sensor on any asset anywhere.
The governance frameworks built in the years that followed continued assuming human speed: that a team of people could describe what data means, keep those descriptions current, and do so faster than the data itself changes meaning.
That gap is now structural. And it was structural before AI agents arrived to consume the data.

The Stack and Where It Works
Heimsbakk’s response to the fidelity critique is substantive. SHACL shapes as the contract layer. Named graphs with provenance as the temporal anchor. Versioned ontologies as the drift signal. SKOS vocabularies as the meaning layer. Four roles: data engineer, knowledge engineer, ontologist, domain expert. The domain expert who knows what a concept means has instruments to express it in machine-readable form. The knowledge engineer turns that expression into a constraint the system can enforce. Governance happens in the substrate.
For organisations whose data is primarily rows, columns, and legally stable codes, this is the right answer. Where meaning is set by regulation, it does not drift.
The stack works when the data is slower than the people who govern it.
The Assumption the Stack Inherits
Every element of Heimsbakk’s durability stack operates at human speed. A knowledge engineer writes a SHACL shape. An ontologist versions the model. A domain expert flags a concept that has drifted. These are human actions, performed in human time, maintained by a team with enough capacity to keep up. This is not a criticism of the model. It is a description of its operating condition. And that condition is becoming rarer.
Page’s observation in 2012 was not about sensor counts or video streams. It was about the relationship between data velocity and decision speed. When business decisions depend on data that is current, not merely recent, the governance cycle that keeps meaning accurate must run faster than the operational cycle that changes it. In 2012 that was already a challenge for a marketplace processing millions of transactions a day. In 2026 it is the default condition for any organisation whose decisions, operations, or customers move at digital speed.
Consider a CRM system updated in real time from every communication channel: email, chat, social interaction, call transcripts. The behavioural data is current. The definition of what that behaviour means, the segment, the offer, the relationship status, was last ratified by a governance team weeks ago. When an AI agent acts on that definition an hour after the customer’s situation changed in a way the definition does not capture, the gap is not a data quality problem. It is a governance model problem: the organisational pattern that keeps meaning current was not designed to run at this speed. The agent acts on meaning that was accurate before the last interaction: a silent contract violation propagating into every recommendation built on it.
Statens vegvesen (the Norwegian Public Roads Administration, NPRA) is close to the work and worth naming precisely, not because it is unique but because it shows where the direction of travel leads when it fully arrives. It manages the physical infrastructure of a nation, and its data spans domains that share geography but not governance.
One regime is standardised. SCADA systems (control systems that monitor and manage physical installations in real time) produce high-velocity, high-volume measurement data whose meaning does not drift. A control point has a defined tag, a defined unit, and a fixed meaning inside a control architecture that is itself standardised. Federating a knowledge graph over that data and pushing aggregation down to a historian is exactly the right architecture. This regime moves fast, but it does not cross semantic boundaries: the category is agreed before the data is queried. Here Heimsbakk’s stack holds, and the velocity is not the problem.
The other regime has no such control model underneath it. Tunnel electro installations, environmental sensor readings, LiDAR scans, drone imagery feeding bridge integrity algorithms, road condition data: the measurement may be standardised, a temperature is a temperature, but the operational significance is not. The same environmental reading means one thing to a winter maintenance contractor, another to a bridge integrity model, another to a nature-warning risk system. A LiDAR scan’s meaning activates only when a specific engineering question is asked of a specific curve. No standardised model fixes the category in advance, because the category is assigned by whichever domain is consuming the data and under what conditions. This is not the larger half by sensor count, and it may not be the faster half. It is the hard half, and it is hard for the reason the rest of this essay names: the meaning crosses operational boundaries, and no single team owns it across all of them.
The same organisation, the same kind of physical asset, two regimes: what separates the governable one from the hard one is not speed and not volume. It is whether the category is standardised and single-domain or contested and cross-domain.
The hard half does not scale with sensor count. It scales with the number of domains that read the same data differently.
The Business Case the Stack Does Not Make
The durability stack is a permanent overhead. In a well-funded organisation with stable domains and bounded data, that overhead is manageable. But every organisation operates with limited headcount and competing priorities. The question a budget holder asks is not whether the architecture is correct but what business outcome justifies this cost against everything else competing for the same people. The benefit of governance is diffuse, hard to measure, and invisible until something breaks. New capabilities always compete more successfully than the sustained accuracy of existing ones.
Data governance has a default answer: add resources. In public organisations that answer has a name: it is a trade-off against the mission. Every governance headcount is the same budget line as a nurse, a road inspector, or a caseworker.
A governance model that requires permanent specialised headcount to sustain it will lose the priority competition in most organisations, most of the time, regardless of its technical merits.
Where the Framework Has No Vocabulary
Orden i eget hus (loosely, “order in one’s own house”) is the Norwegian data governance requirement for public entities. It did not choose its assumptions. It inherited them from the institutions it was built around: large public registers where data is a legal fact that does not change without an act of Parliament, and case processing systems where administrative procedures follow legally defined steps and timelines. In both patterns, data is definitional and slow. Its seven steps ask you to map your data, describe it with metadata, and maintain routines for keeping that description current. They work because the institutions the requirement governs operate in a stable, legally-grounded, human-speed domain.
That is an increasingly narrow class of organisation.
For any organisation whose data crosses operational boundaries, serves multiple contexts simultaneously, or changes meaning as conditions shift, the cartography step is not a process problem. It is a category error. The framework has no tier for data whose meaning is inseparable from its operational context. An organisation cannot score well on that scale by design, not because it lacks discipline, but because the scale was built for a different kind of data entirely.

The Harder Problem
Heimsbakk’s durability stack is the right answer for a specific class of organisation. The industry needs her skills applied to the harder class.
The question is not whether you can afford a team of ontologists. The question is whether human-maintained governance is the right architecture for data that moves faster than humans, across boundaries wider than any single team, serving contexts that shift faster than any description can follow.
Partial automation exists: schema registries, streaming data quality checks, automated validation at ingestion, federated query engines that join a knowledge graph to a time-series store in a single query. These solve the format contract problem, ensuring data arrives and is retrieved in the right shape. They do not solve the meaning problem: verifying that the meaning of the data is still what the consuming system assumes when operational context shifts. A federated query executes meaning quickly. It does not author meaning. That gap is what this argument is pointing at.
A natural response is that governance does not need to match data velocity if it operates at the level of categories and types rather than individual records. That is correct, and it is exactly what the three directions below attempt. Heimsbakk’s four-role model already makes a version of this move: bringing authorship closer to the people who hold the meaning shortens the path from meaning to artefact. A generative pattern goes further still: one OTTR template (a declarative mapping pattern that generates RDF from tabular data), authored once, maps thousands of records into a knowledge graph. But the template scales the reach of a category, not its authorship. Someone still decided what “coastal” means, or that a new station type now exists. SHACL shapes make violations machine-readable. They do not make the authorship of shapes machine-speed. A shape fails loudly when a known field drifts. It fails silently when the category itself is contested across domains, because no single shape holds authority over a meaning that different domains assign differently. Automated enforcement extends the reach of a shape already written. It does not write the shape for meaning that has not yet been described.
The threshold is crossed not when data is fast but when meaning is renegotiated faster than the governance cycle that ratifies it: the periodic process by which teams agree on definitions and update their artefacts. That happens structurally wherever the same data serves domains that read it differently. Raw speed is not the variable. Semantic boundary-crossing is.
The right division of labour changes who authors the categories. It does not change the speed at which the categories can be updated when the same data crosses into a domain that reads it differently. When the same data crosses operational boundaries and means something different in each domain it enters, the category itself becomes the contested object, and the disagreements are harder to detect and more expensive to resolve than format violations ever were.
Three directions worth pursuing are genuinely distinct in mechanism, not only in lifecycle position. Boundary constraints operate at the system boundary before data enters: enforcement happens at ingestion and query time, not at authorship time, removing the dependency on a human updating a shape before the data moves. Dynamic contracts operate on claims already inside the system: they re-verify meaning as operational context changes, so a contract is not a document ratified once but a check that runs continuously against shifting conditions. Consumption-point governance operates at the moment a specific decision depends on the data: validation is deferred to the point of use, so the system can ask whether the data it is acting on is still valid in the current context at the moment action is taken, not at the moment the data was described. The LiDAR case is the worked example: a scan whose meaning activates only when a specific engineering question is asked of a specific curve cannot be validated at ingestion, because the question that determines its meaning has not yet been asked. Validation must travel with the query, not precede it.
None of these is a solved design. But each addresses the silent contract violation at a different point in its lifecycle: before it enters the system, as it propagates through changing context, and at the moment a decision depends on it. That is the problem space where the expertise Heimsbakk has developed is most needed.
AI agents do not create this problem. They close the last window of tolerance. When a human analyst consumes data with stale meaning, they sometimes notice something looks wrong and pause before acting. That pause is the circuit breaker human-speed governance was quietly depending on. An agent acting at machine speed on a knowledge graph built from human-maintained descriptions does not pause. The gap Bob Page named in 2012 was always there. Agents simply make the consequences of leaving it open irreversible.
The durability stack Heimsbakk describes specifies what governance looks like at human speed. It does not specify what the knowledge engineer does when the domain expert cannot flag drift fast enough, or when no single domain expert owns the meaning across all the contexts the data serves. What is the machine-speed equivalent of SHACL authorship? What replaces the ontologist when the ontology needs to update at sensor frequency? These are not questions about resources. At a certain velocity threshold, human-maintained governance does not need more people. It needs a different architecture. That is the design problem the field needs next.
If this exchange has been useful, Veronika Heimsbakk writes at Living Knowledge Graph and the conversation is worth following.
Further reading
Sunday Morning Data Wisdom: Bob Page at eBay: the 2012 observation that the future is live and the business cannot be held back by the slowest data feed, which is the prediction this argument shows was never answered.
The Contract Is the Architecture: develops the distinction between a constraint that holds at a boundary and a description that requires maintenance to stay current.
Where Meaning Comes From: examines the sequencing question underneath governance architecture: whether meaning should precede data or emerge from it, and why emergent meaning becomes load-bearing before anyone has examined whether it is right.
Naive Federation: Centralisation’s Evil Twin: develops what happens when coordination mechanisms are distributed without the authority structures that make them load-bearing under pressure.
The Metadata Coordination Problem: examines why human-speed coordination fails when data moves across boundaries faster than governance processes can track it.
An honest endnote
This essay argues that the durability stack Heimsbakk describes is correct for the organisations it was designed for, and insufficient for organisations operating at the speed Page described in 2012 and beyond. What it does not resolve is what the right governance model looks like for that second category. The directions named here are sketches, not designs. The question is whether the governance model Heimsbakk has developed can be extended to hold under conditions it was not originally designed for.
SVV is named because it is close to the work, not because the problem is solved there. The organisation is on a journey, working to understand what governance it minimally needs while pursuing the operational ambition of improving road safety, reducing maintenance costs, and creating insight that did not exist before. The governance question and the operational question are not separable. That is not a failure of planning. It is the honest shape of the problem.
This is written close to the work. If your organisation is planning a governance team to maintain an ontology for data that moves faster than your governance cycle, the gap between that plan and the budget conversation that follows is where this argument begins.