

Why Your Governance Dashboard Cannot Tell You What Is Wrong
The signal looks familiar. That is exactly the problem.
This essay is the first of two companions to "A Platform Is Never Finished." It develops the exception motion: what happens when exception systems operate without the presence that would make their signals interpretable. The second companion, "The Scaffolding Problem in Data Organisations," develops the presence motion and is best read after this one.
The dashboard shows green. Quality gates are passing. Contracts are enforced. The governance report lands in the right inboxes on the right day. And somewhere in the organisation, a product team has quietly stopped using the certified data pipeline and built their own. When asked why, the answer is simple: the governance logic had been written for last year’s product structure, and the data passing through it no longer means what the governance team thinks it means.
The programme has not failed. It has frozen.
This is the central problem with exception-based governance: it is designed to catch deviations from a baseline, but it cannot tell you when the baseline itself has become wrong. And in organisations under transformation, the baseline is always changing. The gap between what the exception system was designed to catch and what is actually going wrong grows invisibly, quarter by quarter, until a cross-domain decision makes it undeniable.
This essay is primarily concerned with organisations that have functioning exception systems but no presence to interpret what the signals mean. It is worth naming the fuller spectrum: some organisations have no exception system at all, governance is a set of policies in a document nobody reads, and others have the infrastructure of exception systems without the organisational practice of acting on what they surface. Each position on that spectrum has its own failure mode, and this essay addresses only the last. If you are still building the exception system, the argument here is worth reading forward: it tells you what presence you will need before the signals are worth trusting.

The Baseline Problem
Every exception system rests on a set of assumptions about what normal looks like. A quality gate that checks for null values assumes that non-null data is trustworthy. A contract that enforces a schema assumes the schema still reflects the business concept it was designed to represent. An access control that provisions by role assumes that roles still map to the decisions those roles need to make.
When those assumptions were designed, they were correct. They may not be correct now.
The baseline drift problem is structural rather than operational: it does not arise from failure to maintain the system. It arises from the system working exactly as designed while the world it was designed for continues to change around it. Each instance of baseline drift is a specific source of coordination debt, the accumulated cost the parent essay names.
Consider what this means in practice. A domain renames a field to reflect a product restructuring. The change is operationally sound, internally documented, and entirely invisible to any downstream consumer relying on the previous definition. The quality gate still passes. The contract is still honoured, technically. The signal stays green. The exception system is functioning correctly and failing simultaneously.
The exception system cannot catch what it was not designed to watch for, and it was designed before the organisation knew what it would need to watch for.
What Presence Actually Does
The gap between what an exception system was designed to catch and what is actually going wrong cannot be closed by expanding the exception system. Expanding it deepens the assumption that the right instrument just needs more calibration. Closing it requires someone who is close enough to the work to notice that the gap exists.
What closes the gap is not more governance but presence: the disciplined engagement of people close enough to the work to notice when a signal that looks familiar is telling the wrong story. This is not the same as more reviews. A review that asks “did the quality gate pass?” is asking a question the exception system already answered. The question presence enables is different: “is the quality gate watching the right thing?”
That question requires intuition the exception system does not have, built from proximity to the work the exception system cannot develop. Presence is not attending more governance reviews. It is the platform leader who joins a domain team’s actual working session rather than their status meeting, and notices that the team has stopped trusting a dataset the quality gate still passes as clean. It is the data owner who asks why a pipeline was rebuilt from scratch rather than why it broke, and finds the answer in a governance constraint nobody had flagged. It is the senior analyst who flags that two teams are using the same term to mean different things before that divergence reaches a cross-domain report. In each case the signal was green. The person close to the work knew it was not.
A platform leader who knows what domain teams are actually struggling with, not what they report in status meetings, will recognise the moment when a governance signal stops reflecting operational reality. A leader reading a dashboard from a distance will not, because a green signal and a misleading signal look identical from there.
This is why exception systems and presence are not alternatives but prerequisites for each other. Exception systems that work well reduce the noise that would otherwise exhaust the attention presence requires. Presence builds the intuition that makes exception systems interpretable rather than merely legible. Remove the presence and you are left with a system that generates accurate readings of a question nobody is still asking.
The Performance It Produces
The absence of presence from an exception-based governance system produces a predictable organisational response: teams learn to manage the signal rather than the underlying reality.
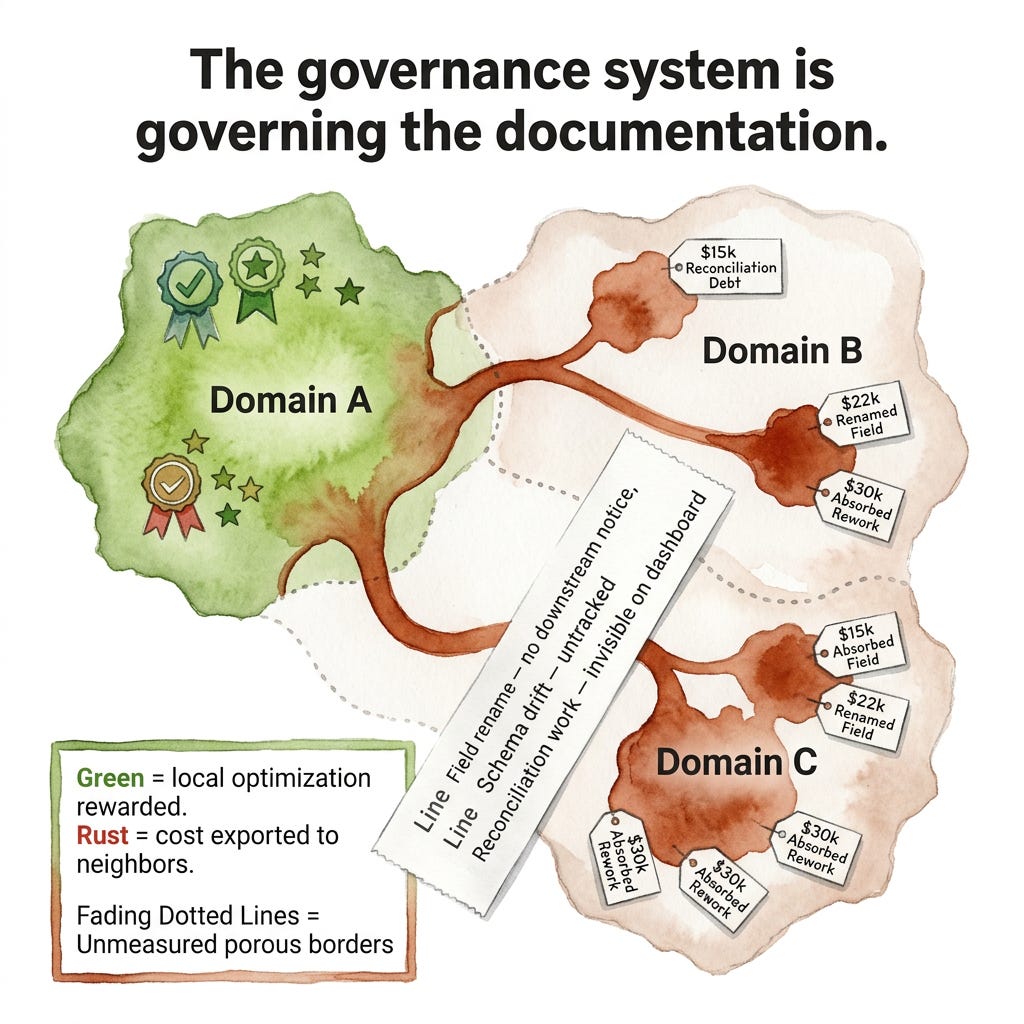
This is not cynicism. It is rational adaptation. When the signal is what gets read and responded to, optimising for the signal is optimising for what the organisation measures. A domain team that understands the governance dashboard will deliver governance dashboard performance. The work required to maintain genuine cross-domain coherence, semantic alignment, downstream notification, contract renegotiation when business concepts shift, registers nowhere on the dashboard and therefore registers nowhere in the quarterly review.
The entropy tax, developed in full in the further reading, names what accumulates at those boundaries. The concept is simple: costs that should appear at their source instead distribute invisibly to the teams absorbing them. A domain that renamed a field without notifying downstream consumers did not fail any governance check. The teams doing weeks of reconciliation work to absorb that change were not visible on any dashboard. On the dashboard, the domain that made the change looks productive.
The teams doing the most damage to collective coherence are often the ones with the strongest governance metrics. Leadership responses calibrated to those metrics will consistently invest in the wrong places and pressure the wrong teams.
Designed Before the Question Was Answered
The baseline drift problem explains how a well-designed exception system becomes wrong over time. But there is a prior problem that compounds it: most exception systems were never designed to watch the right things in the first place.
Most governance frameworks are built to measure what is easy to measure: schema compliance, null rates, pipeline uptime, contract adherence. These are measurable because they are local, because they live within a domain rather than at the boundary between domains. The cost of boundary failures, the reconciliation work triggered when a domain changes without notifying its consumers, the semantic drift that accumulates when domains evolve their concepts independently, is almost never attributed to its source. It distributes across the teams that absorb it, making those teams look like they are struggling with execution when they are actually paying the tax that another team’s local optimisation created.
A governance system that does not make the cost of local optimisation visible at its source is not governing the organisation. It is governing the documentation.
Redesigning the exception system to measure at the boundary rather than only within the domain is technically achievable. The data to support it usually exists. It is politically difficult, because the measurement system currently rewards the domains that are causing the problem and would require attributing cost to them explicitly. That attribution is the point.

What the Dashboard Cannot Tell You
An exception system is not a governance model. It is a governance instrument, and like any instrument it measures what it was calibrated to measure. The distinction that matters is between an accurate reading and the right question. A thermometer cannot tell you whether the patient is getting better. It can only tell you the temperature. Whether that temperature is the right thing to be watching requires a clinician with enough context to know what the reading means, and enough presence to recognise when the reading is accurate but the question is wrong.
The governance dashboard cannot tell you when the baseline has drifted, when a green signal is managing performance rather than reflecting it, or whether the thing it measures still matters. Those are questions that require presence.
An exception system that operates without presence does not just fail to catch what is going wrong. It provides confident, accurate, up-to-date information about a question the organisation is no longer asking.
One diagnostic question cuts through it: when did someone last ask not whether the exception system passed, but whether it was watching the right thing?
The companion essay, “The Scaffolding Problem in Data Organisations,” examines the presence motion of the same argument: what it means for platform presence to build domain capability rather than replace it, and why the difference between scaffolding and load-bearing support is structural rather than a matter of intent. The delegation motion, what it means for domain teams to hold genuine authority rather than nominal ownership, is developed in the further reading entries below.
Further Reading
“A Platform Is Never Finished” — the parent essay: exception, presence, and delegation as a simultaneous system, and what each failure mode costs.
"Why Data Ownership Fails" — develops the measurement system argument this essay's fourth section builds on: why the incentive structure was never designed to make governance rational, and why redesigning what gets measured at the boundary is where governance actually begins.
“The Entropy Tax” — develops the boundary cost mechanism in full: the measurable cost local optimisation exports to the teams depending on it, and why it accumulates invisibly until it cannot be ignored.
“When Governance Has to Keep Up” — the adaptive governance argument: why governance logic designed at a point in time is structurally right when written and increasingly wrong as the world continues to change.
“Why the Best Governance Is Built Into the Platform, Not Bolted On” — the architectural complement: what it means to embed governance in infrastructure rather than administer it through oversight.
Honest Endnote
This essay argues with confidence that exception systems without presence produce legibility without understanding, that the baseline drift problem is structural rather than operational, and that the entropy tax accumulates at boundaries the governance dashboard was not designed to see. Those claims are grounded in how measurement systems actually behave under organisational change.
What it leaves open is more specific: the question of what minimum viable presence looks like in organisations that are genuinely too large for any single leader to be close to all of the work. The argument that presence is necessary is defensible. The mechanisms for distributing it at scale without it becoming a new layer of oversight are not fully resolved here. If you are operating at that scale and watching the governance dashboard drift from operational reality, the comments are the right place to bring what you are seeing.
This is written close to the work. If your governance dashboard is passing green while the people closest to the data are quietly building their own pipelines, the argument here is where the next conversation begins.