

Most data organisations are output-focused. They measure delivery: models shipped, dashboards built, pipelines deployed. They know they should be outcome-focused instead, measuring whether decisions change and whether the business operates differently. But the transition from output to outcome is expensive, slow, and politically uncomfortable. AI tooling has arrived into this gap and made it wider. A data team that once spent six weeks building a churn prediction model now delivers one in six days. The model is competent. The pipeline is clean. The dashboard renders beautifully. And because producing outputs has become so cheap and so fast, the case for doing the harder work of understanding whether anyone will use them feels weaker than ever. The output side of the organisation has never looked more productive. The outcome side has not moved at all.
This is the speed illusion: the belief that faster construction equals faster value creation. AI dramatically reduces the cost of producing outputs while leaving the cost of learning, alignment, and behavioural change untouched. The gap between construction capability and organisational readiness is not merely exposed by AI. It is widened by it.

The Hidden Work That Slowness Was Doing
Most data organisations suffer from three illusions of maturity: empowerment that is performative, progress measured by activity rather than impact, and sophistication that mistakes technical complexity for organisational capability.
The argument behind those illusions assumed a world where building was expensive enough to force certain organisational conversations. When a churn model required six weeks of engineering, the team spent the first two in stakeholder meetings, requirements workshops, and data quality audits. Those activities felt like overhead, and some of it was. But they were also doing alignment work that nobody recognised as alignment work.
Stephanie Leue recently named this mechanism for product organisations. Discovery processes were never just about de-risking the product. They were silently creating alignment on who the buyer is, why they would care, and how to reach them. When AI collapses the build cycle, those conversations disappear: not because anyone decided they were unnecessary, but because the process that forced them no longer takes long enough to create space for them.
The translation to data organisations is the critical move. In product organisations, the missing alignment question is “who buys this and why?” In data organisations, the missing alignment question is “who changes a decision because of this, and how?” The questions are structurally identical: both ask whether the thing being built connects to a behaviour that creates value. Both disappear when construction accelerates past the point where the process forces them into the room. In data organisations, nobody owns this question by default, because data teams are measured on delivery and business teams assume adoption is someone else’s problem.
Slow discovery processes were the only thing that even partially surfaced how the organisation actually made decisions, because stakeholder interviews and requirements workshops exposed decision-making patterns whether anyone intended them to or not. When those processes compress to days, the organisation loses not just the alignment work but the only mirror it had for its own decision-making behaviour.

The Fourth Illusion
AI acceleration introduces a fourth illusion alongside the three above: the illusion of velocity. Where the first three concern what an organisation believes about its capabilities, the velocity illusion concerns what it believes about its rate of learning.
A data team shipping a new model every sprint appears to be learning fast. But output volume is not learning velocity. Learning velocity is the rate at which an organisation updates its understanding of what creates value. A team that builds twelve models in a quarter without discovering which decisions those models should influence has not learned anything.
This is not an accident. AI reduces the cost of building models, generating dashboards, and shipping pipelines. It does not reduce the cost of understanding which business decisions need to change, testing whether stakeholders will alter their behaviour, or measuring whether outcomes actually shift. The result is that output-focused organisations become more output-focused, not less. The fact that none of it connects to changed decisions is harder to see precisely because there is so much of it.
The velocity illusion borrows against what might be called adoption debt: the accumulated gap between data products that exist and data products that change decisions. Every model built without confirming that a named decision-maker experiences the problem it addresses adds to this debt. The debt compounds through credibility erosion: each unadopted product makes the organisation marginally less willing to trust the next one. When data products consistently fail to address felt pain, the organisation routes around them. Shadow systems emerge. Business units solve their own problems. The data team’s standing with stakeholders degrades quietly. The erosion is accompanied by a knowledge problem: the organisational learning that already exists about which data gets used and which gets ignored has never been systematised, and faster construction makes it less likely to be.
The debt is invisible until someone asks the cross-cutting question: “Which of our data products actually influenced a business outcome last quarter?” At that point it becomes visible in a way that cannot be argued with.
The velocity illusion compounds the original three rather than replacing them. Each illusion now operates at higher volume: more unadopted products, more dashboards celebrated in reviews, more impressive infrastructure connecting to nothing. This is where the velocity illusion meets OKR performance theater: goal-setting systems that reward delivery volume while the question of whether anything changed goes unasked. Speed does not introduce new failure modes. It runs the existing ones faster.

When the Gap Becomes a Flood
Data strategy is changed behaviour, or it is nothing. AI acceleration sharpens this to a point.
When building was expensive, a data product that nobody adopted was a disappointing quarter, not a systemic signal. New products arrived infrequently enough that each failure was individually forgettable. When building becomes cheap, the failures compound. Data teams can now produce in a month what previously took a year. The ratio of built-to-adopted deteriorates rapidly, and the credibility of the data function erodes as unused output becomes impossible to ignore.
This is also where the pain problem becomes acute. Data strategies fail when the pain they address is not felt by the people who would need to change. The CFO experiences the lack of integrated reporting as a minor inconvenience because the friction appears downstream, in a team they do not manage, on a timescale that does not map to their quarterly review. The sales team does not feel the data quality issue that keeps the data team awake.
When the data team operated slowly, this misalignment was tolerable: the team could invest time in making the pain visible. AI acceleration removes that buffer. The team is expected to ship fast because the tooling makes shipping fast possible. The organisational work of surfacing pain and creating conditions for behavioural change has not become faster. The gap between construction speed and alignment speed is the speed illusion in its most concrete form.
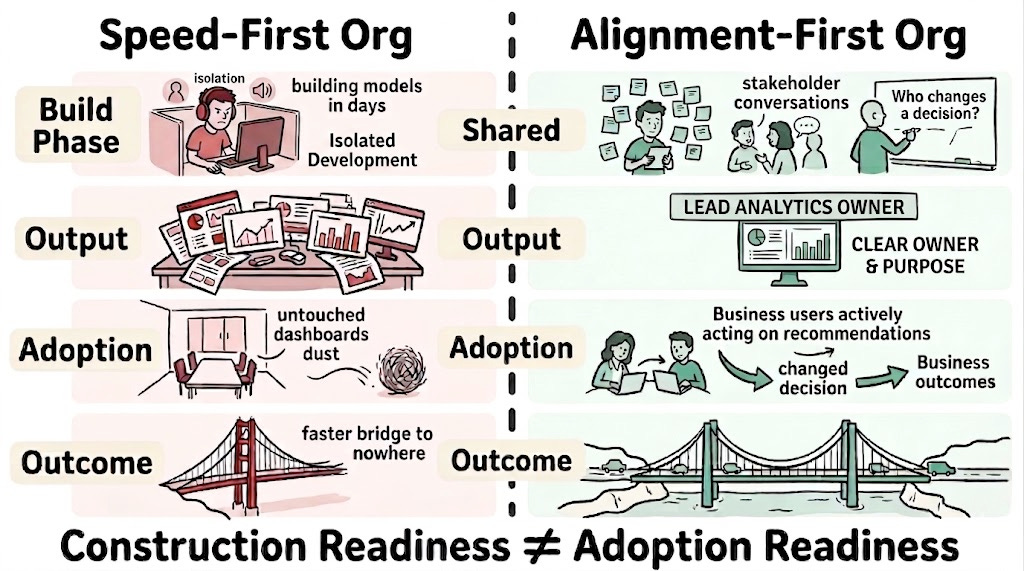
What Speed Actually Demands
The question is whether the organisation can absorb what is built at anything close to the rate it is produced.
A data team that ships a recommendation engine in two weeks has achieved local speed. Organisational speed requires that the product team can consume the recommendations, that engineering can integrate them, and that someone is measuring whether behaviour shifts. None of these are accelerated by AI tooling.
Think of city infrastructure. A construction company that builds a bridge in half the time has achieved a real improvement. But if the bridge connects to roads that have not been built and a transit plan that has not been funded, the faster bridge does not create faster transportation. It creates a faster bridge to nowhere. The bottleneck did not disappear. It moved.
The same structure applies to AI-accelerated data teams. Someone must name the specific decisions a given product is meant to change. Someone must own the adoption question, not the technical delivery question. And the organisation must treat construction readiness and adoption readiness as different things rather than collapsing them into the same milestone.
Stephanie Leue’s argument for product organisations is structurally the same: without a named owner of the market question, discovery disappears and the question disappears with it. For data organisations, the decision question must be owned before the first pipeline is configured.
The organisations that will extract value from AI-accelerated data teams are not those that build fastest. They are those that have reinvested the efficiency gained from faster construction into the learning and alignment work that output-focused organisations have always deferred: understanding which decisions matter, testing whether behaviour changes, and measuring outcomes rather than deliverables. But naming the decision question and assigning adoption ownership are minimum structural conditions, not solutions. They make the gap visible. Until the incentive problem is addressed, the structural conditions create awareness without creating motion. Data teams are rewarded for shipping. The people who would need to champion adoption are typically not measured on it.
The organisations that mistake tool speed for system speed will produce more waste, faster, with better production values. The organisations that recognise the distinction will use acceleration not to ship more, but to learn faster. The gap between the two will widen with every improvement in AI capability.
This essay continues the argument begun in “The Data Product Maturity Illusion“ and extends it with Stephanie Leue’s argument about the alignment work that discovery was doing invisibly.
Further reading:
Data Strategy Is Changed Behaviour (Or It’s Nothing): develops the behavioural test that the speed illusion makes more urgent.
Speed Is a Design Choice, Not a Property of Decentralisation: develops the local-speed-versus-organisational-speed mechanism and the coordination debt concept this essay applies to adoption.
The OKR Performance Theater: names the measurement system failure that accelerates alongside the velocity illusion.
From Targets to Learning: proposes the measurement alternative that would make the speed illusion diagnosable before it compounds.
An honest endnote
This essay argues that AI acceleration does not merely expose the gap between construction capability and organisational readiness; it actively widens it by reinforcing output-focused behaviour in organisations that should be making the transition to outcome-driven learning. What it leaves open is the sequencing question: for an organisation already deep in adoption debt, how does it triage existing debt while building the conditions that prevent new debt from accruing?
That question is harder than it appears. Most organisations carry two burdens this essay names but does not resolve. The first is a habit of avoidance: they have spent years not examining how they actually make decisions, which priorities are inherited rather than chosen, which meetings produce alignment and which produce only calendaring. The second is a knowledge problem: organisational learning about which data gets used, which gets ignored, and why, exists but is scattered at individual and team level, never systematised or connected. Both burdens predate AI acceleration. Both become more consequential under it, because faster construction means less time to discover either one by accident.
There is a counter-argument worth naming. If building has become cheap, could the speed itself be used for alignment rather than against it? Instead of shipping a churn model and hoping for adoption, build three versions in three days and put them in front of decision-makers as experiments. Use prototypes to provoke the alignment conversations that requirements workshops used to force. This is a real possibility, and within a data team running fast experiments it can work. But it addresses a different bottleneck than the one this essay diagnoses. The essay's claim is not that data teams build the wrong thing. It is that the organisation cannot absorb what is built. Each experiment that reaches the consumer side consumes absorptive capacity: the domain stakeholder asked to evaluate three prototypes in a week is not getting better alignment, they are getting more demand on their attention. More critically, faster experimentation does not accelerate semantic alignment. The shared definitions, the cross-boundary agreements about what "churn" or "active customer" or "revenue" actually means, operate on a coordination timescale that prototyping cannot compress. Speed in the laboratory helps when the data team does not yet know what to build. It does not help when the organisation does not yet know how to absorb what has been built.
This is written close to the work. If your data team is shipping faster than ever and the organisation is adopting slower than ever, the gap between those two observations is where this argument begins.